Compound Calibration Part II: The Harness Layer

Every week brings a new model release. Gemini 3 dropped in mid-November, GPT-5.1 days earlier. Opus 4.5 arrived late November. DeepSeek and Grok and Mistral in the mix. The discourse is endless: which one is better, which one to switch to, what the benchmarks really mean.
But the step-change experiences aren't coming from the model releases themselves.
They're coming from Claude Code paired with Opus 4.5, where you point it at a problem and watch it work through dependency conflicts, debug systematically, and finish without intervention. From Cursor with GPT-5.1-Codex, where the agent autonomously implements changes. From Poetiq's meta-system that orchestrates multiple models and beats all of them.
The magic isn't the model. It's how it's wrapped. There's a harness engineering race happening underneath the model capabilities race, and it matters more than most realize.
What the Evidence Shows
Three results from early December make this concrete.
CORE-Bench tests whether AI agents can reproduce scientific papers when given code and data. The team at Princeton ran Opus 4.5 with their standard CORE-Agent scaffold and got 42%. Nicholas Carlini at Anthropic ran the same model with Claude Code and got 78% — an 86% improvement from changing how the model iterates, not from upgrading the model itself. After the team manually corrected underspecified test cases and removed one impossible task, the final score reached 95%.
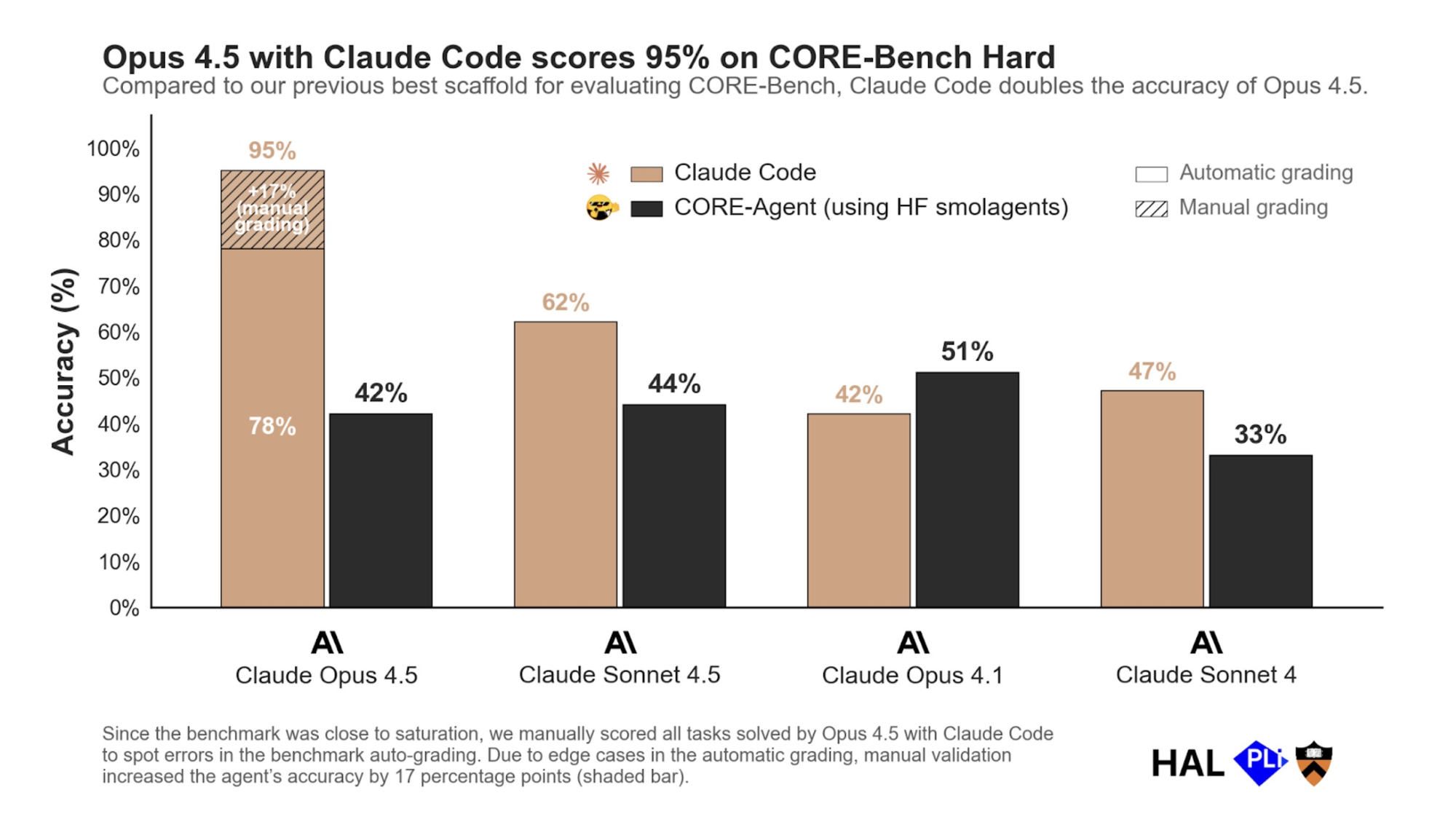
The scaffold change alone delivered the performance jump. The grading corrections just made it measurable.
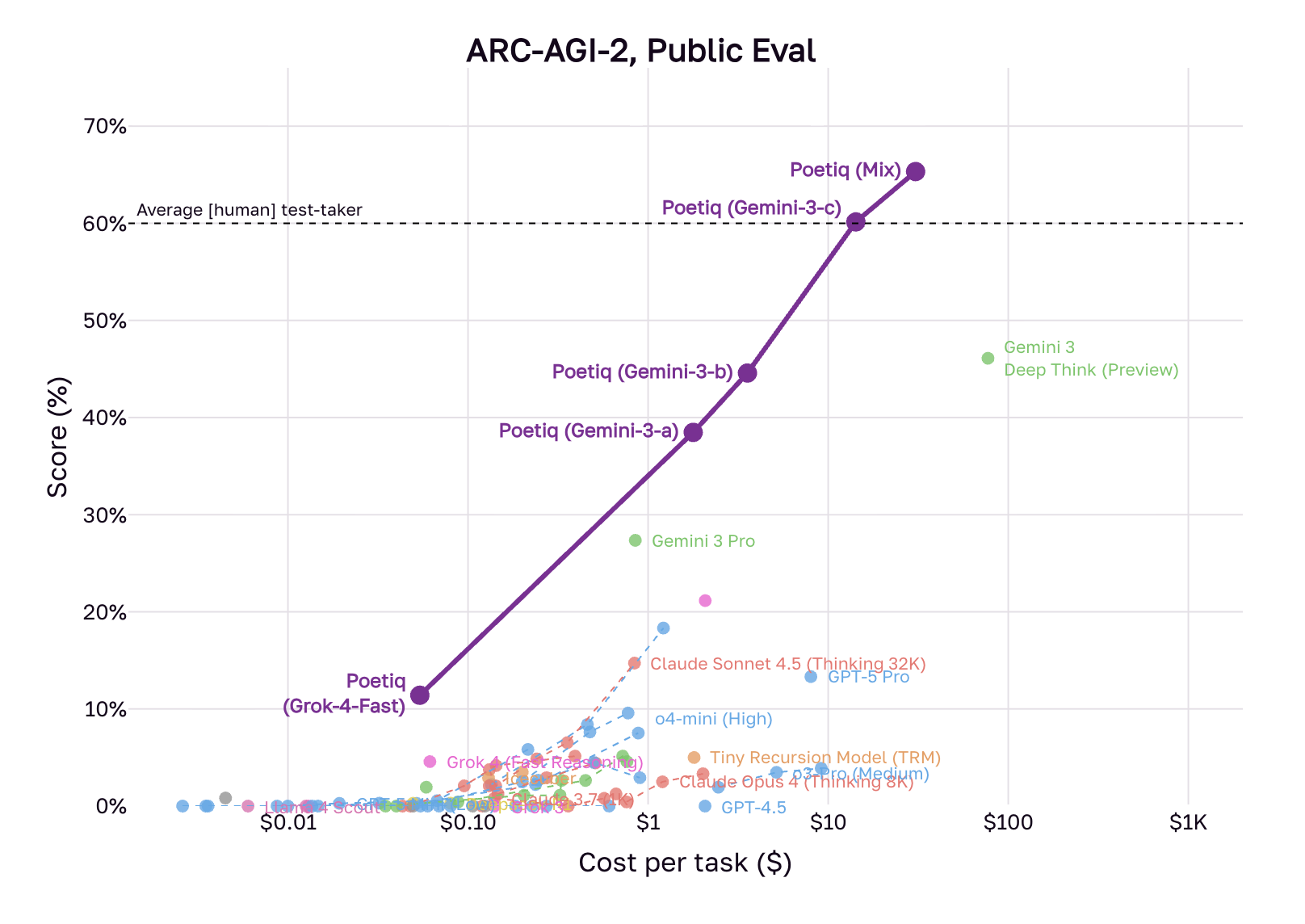
ARC-AGI-2 tests abstract reasoning with visual puzzles. Since the benchmark launched in March, no system had exceeded 45% accuracy. Then Poetiq, a six-person startup, hit 54% at $30.57 per problem using existing models including Gemini 3 and GPT-5.1. Google's Gemini 3 Deep Think scored 45% at $77.16. Poetiq beat Google using Google's model by building better orchestration around it.
Cursor published their harness engineering work for GPT-5.1-Codex. The details matter: they tune tool names to match shell equivalents, add explicit instructions for when to call linters, manage reasoning trace continuity. When they tested dropping reasoning traces, performance fell 30%. Same model, worse harness, 30% performance loss. That's larger than most model upgrades deliver.
The pattern is clear. The model is the engine. The scaffold is the product.
Why the Scaffold Matters
All three systems work the same way. They don't ship first-pass outputs. They generate, test, critique, and refine.
Poetiq's system writes code for puzzles, runs it against test cases, analyzes failures, and regenerates until it passes. Claude Code debugs dependency issues, retries with different approaches, validates results. Cursor ensures reasoning traces persist across turns so the model maintains continuity rather than reconstructing its plan from scratch.
The refinement happens inside the system before humans see anything.
This is different from first-pass calibration with the focus on engineering prompts so outputs need less editing. This is about building systems that improve their own outputs through multiple passes before anyone reviews them.
The layers multiply. Better prompts give you better starting points. Better refinement loops turn those into finished work. If your first-pass output is 70% correct, one refinement pass gets you to 95%.
But here's what matters: Poetiq built their meta-system before Gemini 3 and GPT-5.1 existed. When those models dropped, they integrated them within hours and set new records. Cursor's harness engineering extracted 30% more performance from Codex than a basic integration would. The calibrated harness extracts more value from new models than basic wrappers do.
That's compound calibration at the scaffold layer. Build it once, multiply value with every model upgrade. While teams debate which model is best this week, calibrated systems get better with each release automatically.
Where Effort Goes
Most teams are waiting for the next model. They're switching between providers. They're treating the model as the product and the harness as plumbing.
The CORE-Bench team at Princeton discovered this the hard way. Sayash Kapoor and colleagues built their leaderboard assuming models and scaffolds could be swapped independently. Then they found the same model scores 42% or 78% depending on harness choice. They're now rethinking their entire evaluation approach.
Cursor's experience shows this at production scale. Each new model requires specific harness tuning. The team measures success rates, tracks tool calling patterns, adjusts instructions based on internal evals. When they found Codex wouldn't call their lint tool without explicit instructions, they added them. When they discovered reasoning traces mattered, they built alerting to preserve them.
This is continuous calibration work. Not one-time setup.
The models are becoming commodity. The wrappers are differentiation. And most engineering effort is going toward model evaluation instead of scaffold calibration.
You can see this in how products feel. Claude Code doesn't feel better than a basic chatbot because Opus 4.5 is smarter than other models. It feels better because it iterates, debugs, and validates systematically. Cursor doesn't feel better because GPT-5.1-Codex is a superior model. It feels better because the harness preserves reasoning traces and tunes tool calling. The model capabilities enable it. The scaffold design creates the experience.
Start tracking this. When something works well, ask: is this the model or the harness? When you're impressed by a demo, figure out what's doing the work. It's usually not just prompt quality or model choice. It's how outputs are refined, how tools are orchestrated, how verification runs.
The teams building real moats are calibrating at this layer. They're engineering refinement loops, critique systems, and orchestration. When the next model drops, their systems automatically extract more value from it than competitors who are still evaluating which model to use.
Model releases get the attention. The harness layer is where the compounding happens. Build there.